Recent advancements in multimodal large language models (MLLMs)
have demonstrated a wide range of capabilities, from crafting
poetry based on an image to performing intricate mathematical
reasoning. Despite these achievements, there remains a notable
gap in the systematic evaluation of MLLMs' proficiency in
logical reasoning tasks, which are crucial for practical
applications such as navigation and puzzle-solving.
To address this gap, we propose LogicVista, a
comprehensive evaluation benchmark specifically designed to
assess the integrated logical reasoning capabilities of MLLMs in
visual contexts. LogicVista evaluates general logical cognition
abilities across five core logical reasoning tasks: deduction,
induction, spatial reasoning, numerical reasoning, and
mechanical reasoning. These tasks are further subdivided into
nine distinct multimodal capabilities, providing a nuanced
assessment of each model's strengths and weaknesses.
Our benchmark consists of 448 multiple-choice questions, each
meticulously annotated with the correct answer and the
human-written reasoning behind the selection. This detailed
annotation allows for both open-ended and multiple-choice
evaluation formats, facilitating a thorough analysis of model
performance. The multiple-choice questions are crafted to
challenge the models' understanding and application of logical
principles in visually grounded scenarios. We conduct a
comprehensive evaluation of eight state-of-the-art MLLMs using
the LogicVista benchmark. This evaluation not only highlights
the current capabilities and limitations of these models in
logical reasoning tasks but also provides valuable insights for
future research and development in this area.
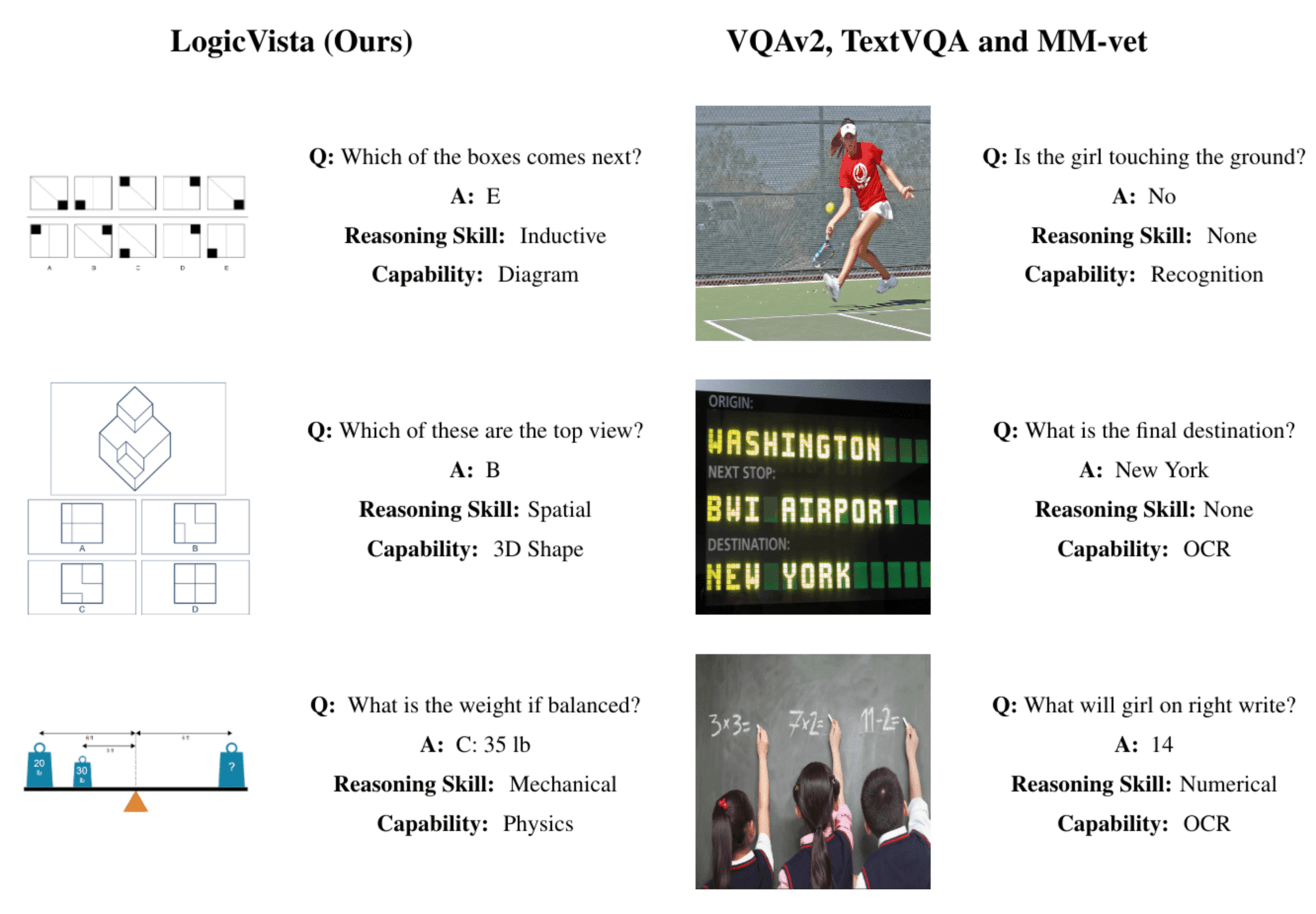
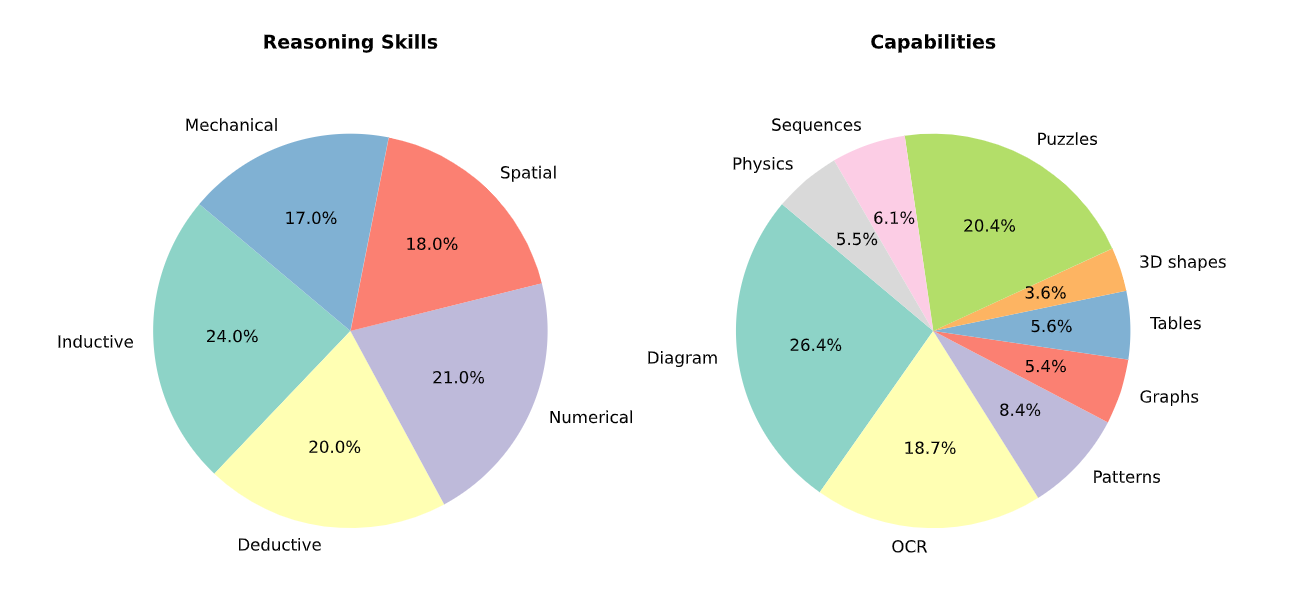
LogicVista is a comprehensive dataset designed for everyday visual logical reasoning. Unlike most current datasets that primarily focus on recognition, LogicVista emphasizes visual reasoning, bridging the gap between recognizing objects and understanding their relationships and interactions. We curate our dataset from 9 close-sourced and liscensed human IQ and reasoning test banks to prevent data leakage. The dataset spans across 5 logical cognition tasks over 9 multimodal capabilities, which highlights richness in the diversity of the samples within our dataset over a variety of visual reasoning challenges. In total, LogicVista includes 448 rich, human-annotated samples of correct multiple-choice answers and explainations of correct answers, enabling for simple MCQ evaluation and open-ended evaluation.
| Model | Inductive | Deductive | Numerical | Spatial | Mechanical |
|---|---|---|---|---|---|
| LLAVA7B | 29.91% | 29.03% | 26.32% | 25.32% | 36.49% |
| LLAVA13B | 18.69% | 31.18% | 20.00% | 27.85% | 24.32% |
| otter9B | 31.78% | 24.73% | 18.95% | 18.99% | 21.62% |
| GPT4 | 23.36% | 54.84% | 24.21% | 21.52% | 41.89% |
| BLIP2 | 17.76% | 23.66% | 23.16% | 24.05% | 18.92% |
| LLAVANEXT-7B-mistral | 16.82% | 34.41% | 23.16% | 21.52% | 22.97% |
| miniGPTvicuna7B | 10.28% | 9.68% | 7.37% | 3.80% | 27.03% |
| miniGPTvicuna13B | 13.08% | 23.66% | 10.53% | 10.13% | 17.57% |
| pix2struct | 12.15% | 6.45% | 2.11% | 7.59% | 17.57% |
| instructBLIP-vicuna-7B | 4.67% | 21.51% | 24.21% | 2.53% | 22.97% |
| instructBLIP-vicuna-13B | 3.74% | 10.75% | 18.95% | 5.06% | 17.57% |
| instructBLIP-flan-t5-xl | 23.36% | 22.58% | 22.11% | 7.59% | 33.78% |
| instructBLIP-flan-t5-xxl | 17.76% | 30.11% | 24.21% | 20.25% | 22.97% |
| LLAVANEXT-7B-vicuna | 26.17% | 21.51% | 25.26% | 27.85% | 29.73% |
| LLAVANEXT-13B-vicuna | 22.43% | 22.58% | 26.32% | 26.58% | 25.68% |
| LLAVANEXT-34B-NH | 20.56% | 52.69% | 30.53% | 24.05% | 40.54% |
@misc{xiao2024logicvistamultimodalllmlogical,
title={LogicVista: Multimodal LLM Logical Reasoning Benchmark in Visual Contexts},
author={Yijia Xiao and Edward Sun and Tianyu Liu and Wei Wang},
year={2024},
eprint={2407.04973},
archivePrefix={arXiv},
primaryClass={cs.AI},
url={https://arxiv.org/abs/2407.04973},
}